Author: Marco Celon
Published on: April 2, 2013
Time: 3:05 PM
Web Address: http://thoughtsoncloud.com/index.php/2013/04/high-availability-in-the-cloud-an-openstack-approach
Article Reference: Thoughts on Cloud

IBM Cloud Products and Services - Cloud computing conversations led by IBMers
High Availability in the Cloud: An OpenStack Approach
Recently there has been a lot of discussion about the maturity of some areas of the OpenStack project (Gartner, Forrester). In the technical community, one recurring thread focused on high availability (HA) capabilities and testing. High availability—ensuring production-grade systems remain available despite node failures—was not a new concept, having been addressed in many software products over decades. However, integrating HA patterns effectively across complex cloud platforms still posed practical challenges. As a result, organizations deploying OpenStack needed to complement platform capabilities with HA constructs, often drawing from proven infrastructure patterns outside the cloud.
IBM has already articulated several studies and technical proposals for this topic, and I encourage you to read this white paper as well as to connect to this developerWorks article.
To expediently address the concerns of HA in Openstack, a solution that covers the Platform Services (Relational DB and Message Broker) has been presented and documented in the San Diego Openstack Summit and starting from the Folsom release, it focus on using a Pacemaker / DRBD combination to achieve HA for both MySQL and RabbitMQ, to notice that many Pacemaker Resource Agents for specific Openstack components are available for download from GitHub.
OpenStack HA Architecture Overview
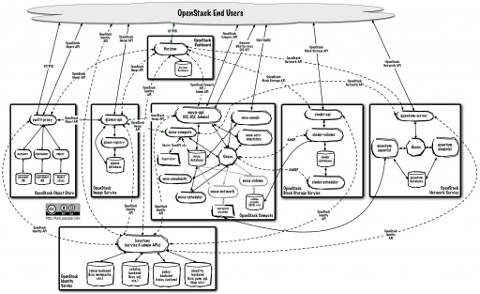
OpenStack HA - End-to-End User Deployments
Although Pacemaker is a well proven tool in the Linux space it seems that work and evolution is still needed on Openstack to both recover some HA gaps from other cloud platforms like Amazon and Eucalyptus and to define the best practices for HA on OpenStack.
Key Recommendations for High Availability
-
Agree on specific HA patterns, eventually base on different deployment topologies, as several and different application scenarios are actually needed and exposed. (MySQL/Galera, XtraDB Cluster, MultiMaster Replication Manager)
-
Define a structured documentation for HA in Openstack, as bits of information can now be retrieved as part of specific components (Nova in the Wiki (NovaDb, RabbitMQ) and in the new section we already exposed.
-
Collect and correlate all the HA functions already present in other areas of the project like in the Storage (Ceph) and Objects replication (Swift).
The request for HA functionalities is coming directly from the Enterprise adopters of Openstack and as the community as already started to give answers I am sure that in the next Grizzly release it will be possible to see and leverage the effort that is undergoing so that the Openstack ability to be a reference choice for Enterprise cloud deployments will be demonstrated.
About Marco Celon

Marco is an IBM cloud delivery specialist based in Australia. During his IBM tenure (2006-2012), he worked across three regions: Italy (2006-2010), Dubai/Middle East (2010-2012), and Australia (2012), with involvement in cloud proposals for SW Europe, MEA, and APAC markets. He is currently engaged with private cloud implementations in the Australia/New Zealand region.
This blog post was originally published on Thoughts on Cloud, an IBM Cloud Products and Services platform for cloud computing conversations led by IBMers.